论文的观点是从一个小规模的样本训练集训练得到一个初始的分类器,然后用这个分类器对大规模训练集进行修剪,修剪后得到一个很小的约减集,再用这个约减集进行训练得到最终的分类器。
文中有一个图很好的解释了他的算法:
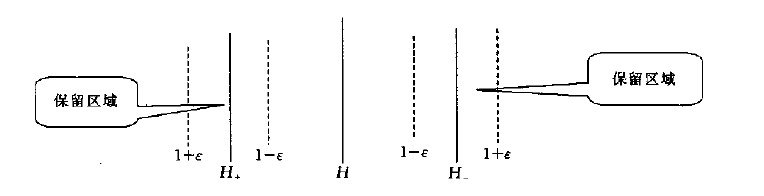
其中H表示分类超平面,H+表示正样本的支持向量所处的超平面,H-表示负样本的支持向量所处的超平面。设样本中任意样本到H的距离为d,则 ,如图所示。算法分三步:
,如图所示。算法分三步:
1:从所有样本中随机选取一小部分样本,在这小部分样本中训练得到一个初始的分类器
2:计算所有样本中的每个样本到刚才分类器的分类超平面的距离,如果满足,则保留此样本放进约减集,否则删除此样本。其中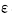 由自己控制,有两个功能:1)控制约减集的规模;2)影响最终分类器的分类精度
由自己控制,有两个功能:1)控制约减集的规模;2)影响最终分类器的分类精度
3:根据约减集的样本再此训练,得到最终的分类器,此约减集已经比初始样本大大减小了,但是保留了大部分的支持向量(因为我们知道,非支持向量对最终的分类超频面是没有影响的)
此文在他的数据集中表现的很好,当我认为也会有一些问题,因为一开始得到的初始分类器不一定接近真实的分类器,这样在删减样本的时候可能会删减最终的支持向量而得不到最优的训练样本。
分享到:





相关推荐
机器学习SVM(支持向量机)实验报告.pdf机器学习SVM(支持向量机)实验报告.pdf机器学习SVM(支持向量机)实验报告.pdf机器学习SVM(支持向量机)实验报告.pdf机器学习SVM(支持向量机)实验报告.pdf机器学习SVM(支持向量机)...
代码 基于SVM支持向量机算法的降水量预测模型代码代码 基于SVM支持向量机算法的降水量预测模型代码代码 基于SVM支持向量机算法的降水量预测模型代码代码 基于SVM支持向量机算法的降水量预测模型代码代码 基于SVM支持...
支持向量机回归和分类的一些练习案例,帮助理解SVM算法
回归,支持向量机(Support Vector Machine,SVM)是Corinna Cortes和Vapnik等于1995年首先提出的,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。...
支持向量机回归SVM完整数据和代码支持向量机回归SVM完整数据和代码支持向量机回归SVM完整数据和代码支持向量机回归SVM完整数据和代码支持向量机回归SVM完整数据和代码支持向量机回归SVM完整数据和代码支持向量机回归...
完整的实现了机器学习算法——支持向量机(SVM),同时通过交叉验证求解最优C值
本资源包括使用支持向量机(SVM)算法进行人脸识别预测的全部源码 SVM就是帮我们找到一个超平面,这个超平面能将不同的样本划分开,同时使得样本集中的点到这个分类超平面的最小距离(即分类间隔)最大化。 支持...
支持向量机svm,支持向量机svm数据生成工具
SVM支持向量机分类鸢尾花数据集iris(jupyter实现) 附带可视化图片
本项目用于演示使用Scikit-learn实现支持向量回归(SVM),并使用Matplotlib对结果进行可视化。该SVM模型应用于波士顿房屋数据集,并绘制预测值与实际目标值的对比图。 使用说明: 运行Python脚本:python svm.py,...
使用SVM支持向量机训练minst数据集
支持向量机:支持向量机(Support Vector Machine, SVM)是一类按监督学习(supervised learning)方式对数据进行二元分类的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大...
支持向量机SVM入门1-3支持向量支持向量机SVM入门1-3机SVM入门1-3
SVM支持向量机分类鸢尾花数据集iris及代码,数据集有Excel、data、txt文件格式,代码有data、txt格式演示
支持向量机matlab实例及理论,详细介绍了svm理论以及MATLAB自带的SVM分类用法
(3) Main_SVM_One_Class.m --- One-Class支持向量机 (4) Main_SVR_Epsilon.m --- Epsilon_SVR回归算法 (5) Main_SVR_Nu.m --- Nu_SVR回归算法 另附: (1) 目录下以Main_开头的文件即是主程序文件,直接按快捷键F5运行...
支持向量机SVM所使用的数据集,包括非线性数据集train_kernel.txt 及test_kernel.txt;train_linear.txt 及test_linearl.txt;train_multi.txt 及test_multil.txt。
鲸鱼优化算法+SVM支持向量机
对多分类支持向量机几种算法进行分析, 系统地比较了各种算法的性能